A wide variety of problem areas are being covered with the help of the field of Artificial Intelligence. Different problem areas need to be tackled or solved in different ways since different algorithms deals different problems in their own ways. Hence, certain algorithms are better than others in when applied to problems with varying environments. In this chapter, we will learn about various algorithms used in to create various AI models which deal with a variety of problem areas. But before moving on with the details of these algorithms we should know what a model actually is.
What is an AI Model?
An AI Model is made up of a mathematical algorithm. It has been trained on a set of data (called the training set). It is used to identify certain types of patterns. Hence, we can say that a model is a distilled representation of what has been learned by a machine learning system.
AI model uses various algorithms to reason over and learn from this data.AI model replicates a decision process to enable automation and understanding. The model should be able to reveal the rationale behind the decision-making process.
AI Models -Working Principle
The AI model works as follows:
- AI models first take up a request in the form of input data.
- It then processes this data and makes predictions.
- After processing, it gives a response as an output.
Now let us learn about the various algorithms used in order to create these AI models.
AI Models – Algorithms
We already know about various types of Machine Learning in AI in our previous chapter. These learning methods make use of different algorithms. Some of the most popular algorithms used in AI models are listed below.

Let us talk about these now.
Decision Trees
This is one of the oldest, simplest, most effective and mostly used methods for supervised learning. Decision trees can be applied both in regression as well as classification.
Working of Decision Trees
In decision trees first a question is crafted carefully. Now, based on the attributes in the question, an answer is reached. Each time an answer is reached, another follow-up question is put up. This follows on until a concluding node is encountered which reverted back as the output for the specific input parameter set.
A decision tree is made up of nodes. These nodes are of three types. These are:
- Root Node – This is the starting node for a decision tree. This node has no incoming edges and it may or may not have outgoing edges.
- Internal Nodes – These nodes lie between the root node and the leaf nodes. These nodes are identified by only one incoming edge and more than one outgoing edges.
- Leaf or Terminal Nodes–These are the end nodes of a decision tree. These nodes have one incoming edge and no outgoing edge.
A classic decision tree contains test conditions which have a decision in a Yes or a No. based on the decision, the model progresses until it reaches the result or leaf node.
Let us consider an example decision tree. Let us put up a question for taking a decision regarding a job offer. The tree would be as follows:

Hunt’s Algorithm is one algorithm which is used as a basis for many existing decision trees.
Artificial Neural Networks
Artificial Neural Networks tries to simulate the human brain. Its composition is similar to that in humans. These networks consist of processing elements called neurons which are inter connected and work together in order to produce an output.
Neural network systems are self-adaptive systems. They acquire knowledge from the environment and use it in order to solve unforeseen problems. Each neuron has an activation level. This value ranges between a maximum and a minimum value.

The inputs (x1, x2, x3, …, xn) and the corresponding weights (w1, w2, w3, …., wn) typically have real values (both positive or negative).
The Perceptron was one of the earliest neural network models. It was invented by Rosenblatt in the year 1962. The Perceptron consists of weights, summing unit, and the threshold processor.
Neural networks offer input-output mapping, fault tolerance, non-linearity as well as adaptivity. But it does not guarantee generalization. Hence, it is difficult to ascertain when the network is trained sufficiently.
Regression Analysis
In AI Models, Regression is a mathematical approach in which we find relationship between two or more variables. In this one variable is known as an independent variable whereas the other variable is referred to as a dependent variable.
Regression Analysis is a part of supervised learning. It is used to predict the behaviour of one variable (i.e., dependent variable) depending on the value of another variable (i.e., independent variable).
Linear Regression
Liner Regression is the simplest form of regression. Here, both the independent variable as well as the dependent variable shows linear nature. Depending on the given data, a graph is plotted and a line of best fit is calculated. This line is hence known as the Line of Regression. Now, based on this line, various predictions are made by the AI system.
Linear regression algorithms are used in financial, insurance, marketing, banking, healthcare and other industries to optimize statistical data.
Logistic Regression
Logistic regression is used to predict the probability of a particular variable depending on the value of the independent variables. This model is used in classification problems like detection of human diseases, cancer detection, spam email detection etc.
The graphical representation of this is similar to the sigmoid function. A sigmoid function is another mathematical function which has an S-shaped curve.
There are three types of logistic regression. These are:
- Binary
- Ordinal
- Multinominal
Linear Discriminant Analysis (LDA)
This is a branch of Logistic Regression model. This is a dimensionality reduction technique. This is used when more than two classes can exist in the output. This technique helps in separating the best classes related to a dependent variable. Hence, it comes under supervised algorithm and is widely used in classification problems.
The LDA has statistical properties of the data for each class. So, if there are n number of independent variables, then this algorithm will extract p <= n new independent variables which separate most of the classes of the dependent variable.
Linear Discriminant Analysis comes under important AI Models and is applied in fields of medicine, face recognition, customer identification etc.
Support Vector Machines
In 1992, Support Vector Machines or SVMs were first introduced by Boser, Guyon and Vapnik in COLT-92. SVMs are a part of supervised learning methods. These are used for classification as well as regression analysis.
SVM is popularly used when using pixel maps as input. As SVMs have high accuracy as compared to neural networks, so they are also used in applications requiring face analysis and hand writing analysis.
The main purpose of SVMs is to create a line known as the hyperplane which separates the data points in n-dimensional space. This enables it to classify any new data points into a particular class. The points closest to the hyperplane are selected. These points are known as support vectors.
SVMs use functions of the original inputs as inputs for the linear function. These functions are called kernel functions. The SVMs are applied to a wide range of data normalization problems.
Bayesian Networks
Bayesian Networks are the computer technology used to deal with probabilistic events. The other names of Bayesian Networks are: decision network, Bayes network or Belief network.
Bayesian Networks are used to solve problems which are uncertain. Bayesian Networks represent the problem using a set of variables. The relation between these variables and their conditional dependencies are shown using a directed acyclic graph.
As the real-world applications are probabilistic in nature so Bayesian Networks work on this principle. The graph which helps make decision making easy in Bayesian Networks is known as an influence diagram. A basic Bayesian Networks graph is as follows:

Here, Nodes represent various variables which may be continuous or discrete. The Arcs represent the conditional probability between these variables.
Bayesian Networks are used in the fields of predictions, diagnostics, reasoning, anomaly detection, automated insight etc.
k Nearest Neighbours
This algorithm is one of the go to algorithms used in AI. It is non-pragmatic and easy to implement. It even has a low calculation time. Hence, this algorithm is used in regression as well as classification problems.
This algorithm uses the technique of nearest neighbours in order to predict the cluster in which the new data point lies in. in order to achieve this, a most favourable value of k needs to be found out. This is usually found using the Elbow method.
This algorithm is applied in recommendation systems like Netflix or YouTube, Image recognition, hand writing recognition, detecting fraudulent transactions etc.
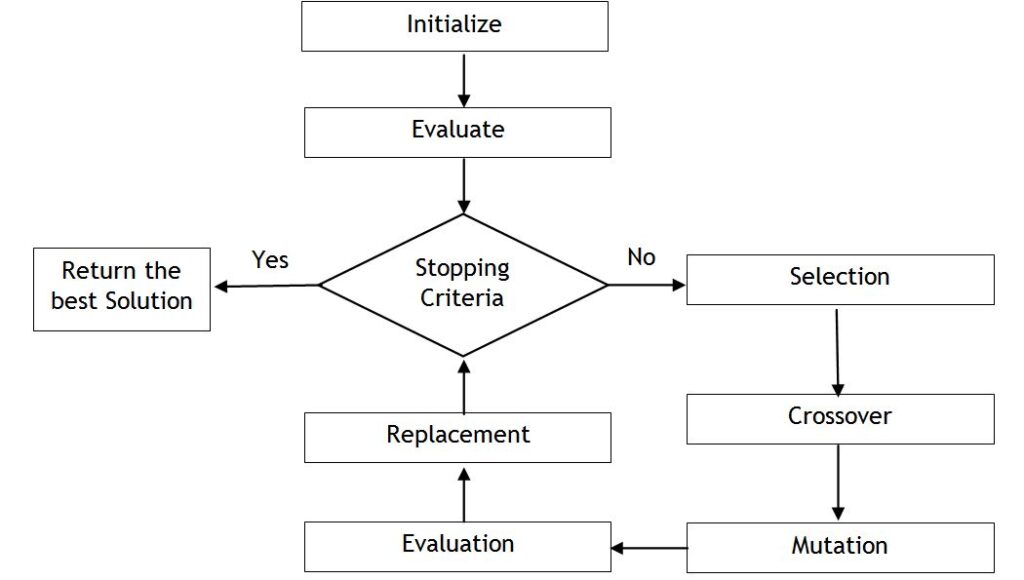
Genetic Algorithms
These are one of the Heuristic algorithms used in AI. These algorithms solve optimization problems. The steps in which a genetic algorithm works is shown in the diagram below.